
A recent blog post by Christian outlines an algorithm that we formulated for the co-optimization of structure and control of robots. This algorithm seeks to more tightly couple the co-optimization as compared to the algorithm described in [1]. Let's call the algorithm we propose Algorithm 1. Algo...
Jointly Learning to Construct and Control Agents using Deep Reinforcement Learning https://arxiv.org/pdf/1801.01432.pdf This paper optimizes parameters in a given robot’s structure and neural network based controller concurrently using policy gradients. The work presented in the paper applies this a...

This past week me and Prathyush worked on formulating an algorithm to use to co-optimize structure and control. Due to the difference in how geometric and control parameters may affect the robot's reward, past research has separated the optimization of the two, choosing to iterate between optimizing...

Over the past week I have been working on assembling a hardware implementation of a robotic localization system. The robot itself is the LEMUR paperbot or segbot that runs on two wheels with its tail dragging behind for stability. The robot has three external sensors, 2 range finding Lidars and one...
I jsut finished the draft of the submission to CDC this week. The paper this time is quite abstract. Even though I tried my best to write it, I still feel it could be better with ideas from others. Hope you can read it and give feedback. Thanks a lot. link
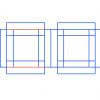
This week, the function for adding finger joint was improved. Now we can add joint to any edges that have the same length. When the dimention of edge is suitable to add finger joint with the selected material thickness, the finger joint will be added. Otherwise, we will automatically add glue joint...
This week, I worked on implementing an API that the PGPE algorithm can use to train the parameters for the neural network that controls the robot as well as the parameters that dictate the robot's structure. Gym is a framework that contains a collection of preset environments that machine learning m...
This week, I spent most of time on reading reference to find the way to decrease the thredshold to actuate the bistable beam. As far as I know, there are several ways to achieve it. One of them is to move the actuation spot close to midpoint of bistable beam. And I modified my design according to th...
I sadly found out that my current result on CI+KF only works in a very limited scenario. The goal is to prove that CI step can diminish the unobservable space, which means that the information can be meaningfully cascaded by CI step. However, by rigorous defining the algorithm, the information fro...
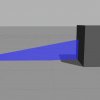
Over the past week, I've been working on measuring the state of the simulated segbot that we have built in Gazebo. Gazebo has 2 main kinds of state acquisition methods. First, we can attach sensors such as lidar or laser beams to the seg_bot model and use a plugin to read those sensor values, which...