
Goal It is common to test and to compare algorithms on synthetic data. Some properties might be more noticeable when we can control the data generating process. In addition, it also helps debugging. Forster et al, IEEE Trans. on Robotics, 2017 Sjanic et al, IEEE Trans. on Aerospace and Elect...

For explicit-landmark optimization-based SLAM systems, the skeleton of SLAM backend can be considered as a nonlinear least-squares optimization problem, or \((\hat{s}_{1:n}, \hat{\lambda}) = {arg\,min}_{({s}_{1:n}, {\lambda})}\, \sum_{t=0}^{n-1} \| s_{t+1} - f(s_t, u_t) \|^2_{Q} + \sum_{t=1}^n \| o...

At first, I started with the okvis project to build my own BOEM SLAM. After spending several weeks understanding what is going on in that well-established project, I realized that there is not way to develop and to test on that project. What I need is to build a project with smaller scale that I can...
There are several existing visual-inertial SLAM implementations. Among all, I pick okvis as our development basis. However, the okvis project is too well-written with sophisticated implementation. There are also some building problem. In summary, it is pretty hard for us to develop, especially fro...

To complete the CoRL submission, I put all the simulation code here. The simulation code compares 4 algorithms, including EKF, LG-EKF, hybrid representation, and fully circular representation.
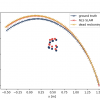
I wrote a 2D SLAM simulation on Python as a starting point. I implemented the nonlinear least squares (NLS) SLAM. To be specific, it is just to solve: \((\hat{s}_{1:n}, \hat{\lambda}) = {arg\,min}_{({s}_{1:n}, {\lambda})}\, \sum_{t=0}^{n-1} \| s_{t+1} - f(s_t, u_t) \|^2_{Q} + \sum_{t=1}^n \| o_t -...
This paper reviews several implementations in artificial intelligence that have neuroscience correspondence. The most robotics-related one is the neuro-replay. In RL, especially navigation related tasks, the performance will be better if the agent stores a certain amount of raw data. The data will b...
I found a paper from DeepMind last year on state representation. This paper integrates state representatin learning with deep reinforcement learning. The authors try differnt loss functions related to state representation, and determine which combination of loss function gives the better performance...
Classic approaches to tackle simultaneously localization and mapping (SLAM) are based on estimation problem. That is, robots try to estimate it position as well as landmark concurrently where both positions are modeled as random variables. A series of works formulate SLAM differently by modeling t...
We studied the paper “A solution to the simultaneous localisation and mapping (SLAM) problem” together this afternoon, and I found out several serious concern about this seminal paper, who has more than 3000 citation. The paper gives 3 main theorems for the extended Kalman filter (EKF) formulation...