Scalling Lifelong Multi-agent Path Planning via Local Field of View
Pehuen Moure reinforcement learning multi-agent path planning
Scaling multi-agent solutions is difficult due to the exponentional growth in state space. To this end we are implementing a local field of view for each agent. Each agents local goal will be determined by running A* over the entire space and finding the last position in the field of view. This follows some of the approaches of existing literature for scaling reinforcment learning based path planning algorithms.
The implementation of the local field of view for the environement is demonstrated in the set of images below:
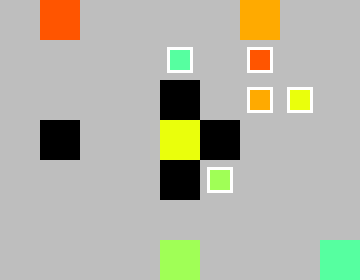
Each agents field of view:




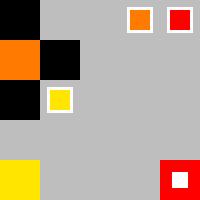
Using this approach we can now scale our agents to work on much larger environments using the same trained agent from a much smaller environment. Below is the approach on a large sparse environment:

Additionally we can evaluate on a much dense large environment:
