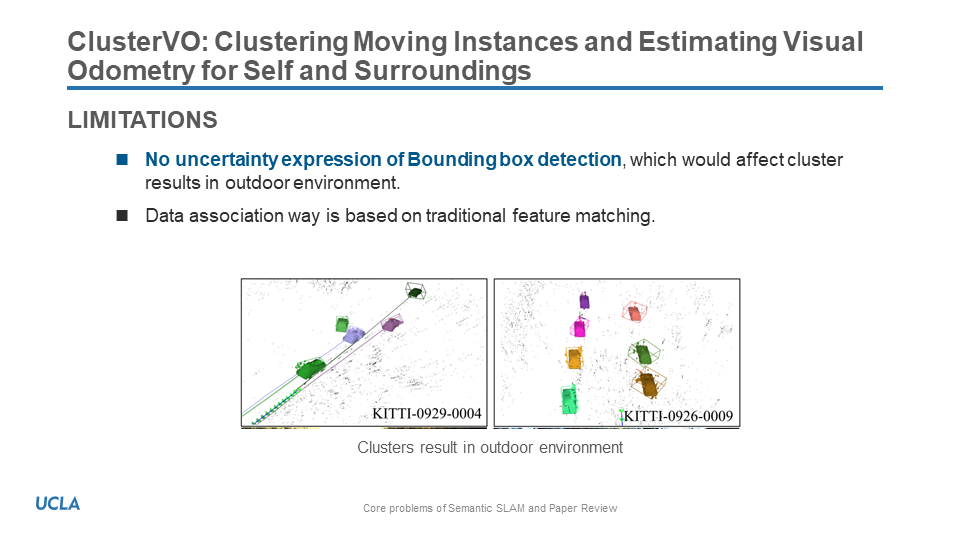
This slides present the semantic core prolems and review four representative papers. Further, it told the main problems we met and the potential solutions to those problems.
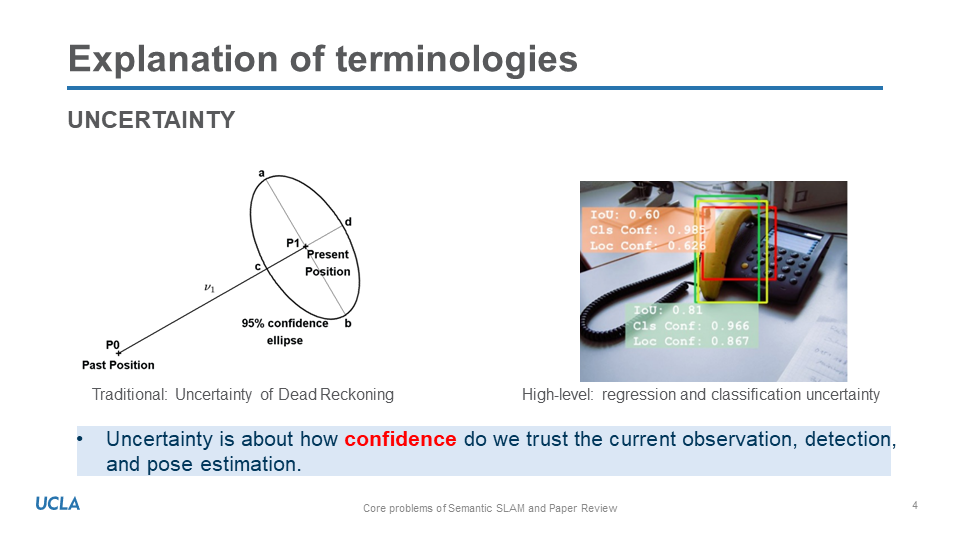
For a brief, the most thing we caring about is the uncertainty of detection or segmentation. Rather than discrete probabiliy map of semantic objects, we prefer to use continous probabiliy description of uncertainty. Moreover, we need more reasonable description of uncertainty considerting both regression and classficication uncertainty.
- This paper [1] tried to estimate both regression uncertainty and classification uncertainty, while if you know YOLO only provides a "score" to describe the uncertainty of bounding box.
- This paper [2] and this paper [3] tried to find which area in detection is most reliable (owns the highest confidence).
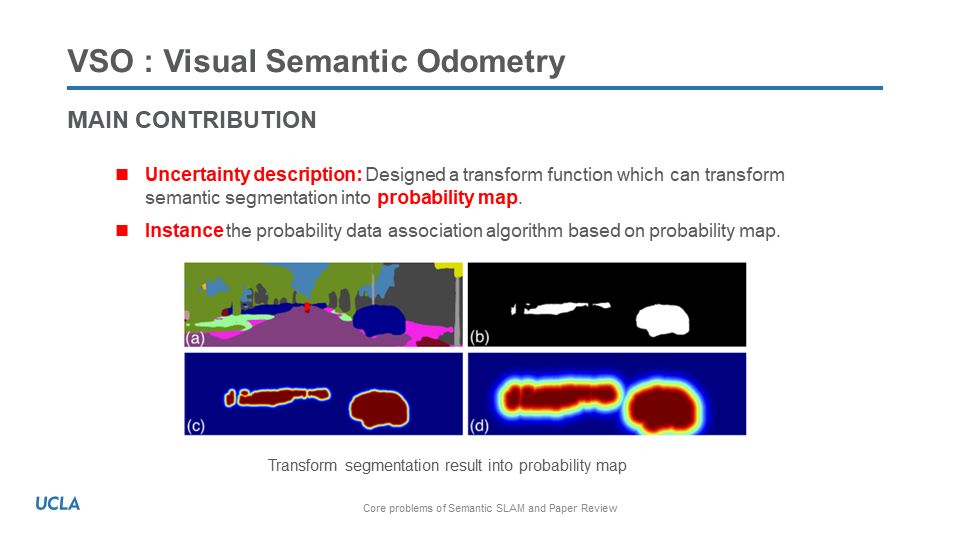
- This paper[4] provides a native but meaningful way to transfer detection into continoues probability descirption of uncertainty. Those are all based on a 2D bounding box and detection network, so I think if there is a segmentation network or 3D Cube with an uncertainty description of regression and classification, as well as a probability map within the object area, it would be very meaningful.
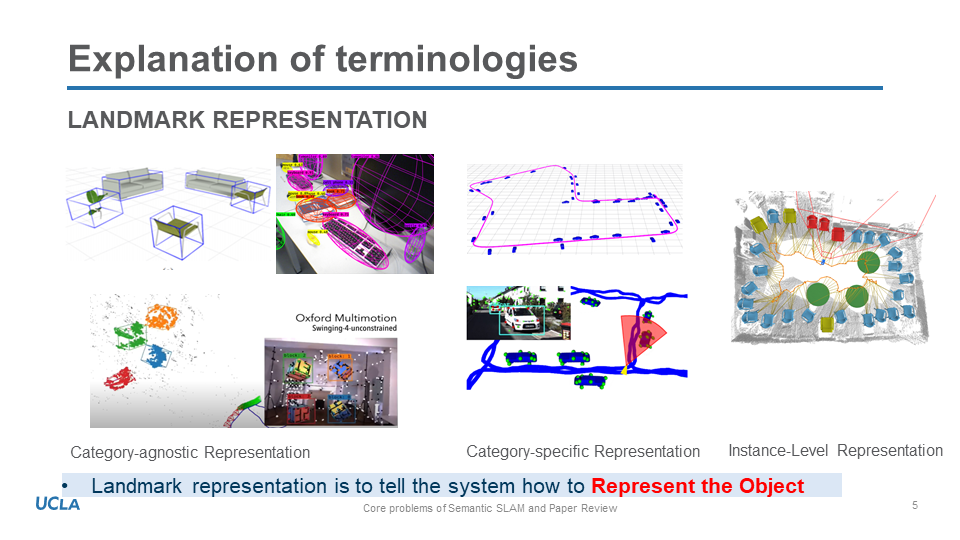
Further, if we want to use high-level desriptor of semantic objects rather than ORB feature, I think the semantic grammer based on graph structure is a promising direction, similiar way as this paper [5]
[1] Jiang, B., Luo, R., Mao, J., Xiao, T., & Jiang, Y. (2018). Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 784-799).
[2] Zhu, B., Wang, J., Jiang, Z., Zong, F., Liu, S., Li, Z., & Sun, J. (2020). Autoassign: Differentiable label assignment for dense object detection. arXiv preprint arXiv:2007.03496.
[3] Liu, W., Liao, S., Ren, W., Hu, W., & Yu, Y. (2019). High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 5187-5196).
[4] Lianos, K. N., Schonberger, J. L., Pollefeys, M., & Sattler, T. (2018). Vso: Visual semantic odometry. In Proceedings of the European conference on computer vision (ECCV) (pp. 234-250).
[5] Liu, X., Zhao, Y., & Zhu, S. C. (2017). Single-view 3D scene reconstruction and parsing by attribute grammar. IEEE transactions on pattern analysis and machine intelligence, 40(3), 710-725.