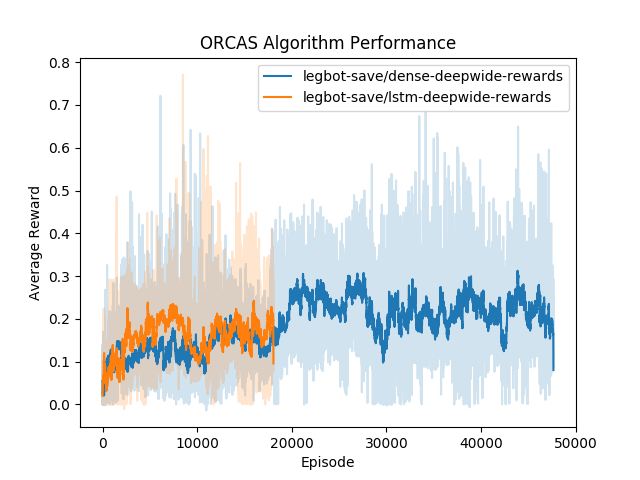
This week I spent a lot of time fixing stability bugs with the ORCAS system and gathering data with the reinforcement learning system. With a learning system, stability is extremely important as learning can takes days or even weeks which means that any small issue can completely bring down the whole system. I came across a lot of these issues while I attempted to train a deep neural network controller for a walking robot. Along with fixing these issues, I spent a lot of time optimizing hyperparameters and coming up with neural network architectures that would learn the controller the best. So far, the most promising results seem to be coming from a three hidden-layer fully connected neural network with 64 units and a ReLu activation. The network was optimized using Adam with a 1e-3 learning rate. The graph above depicts the average reward over time for this set of parameters.
Another promising architecture that we discovered is essentially the same as the above one but with the last fully connected hidden layer replaced with an LSTM cell. We have not run this for as many iterations, but it seems to be at least as good as the dense architecture.
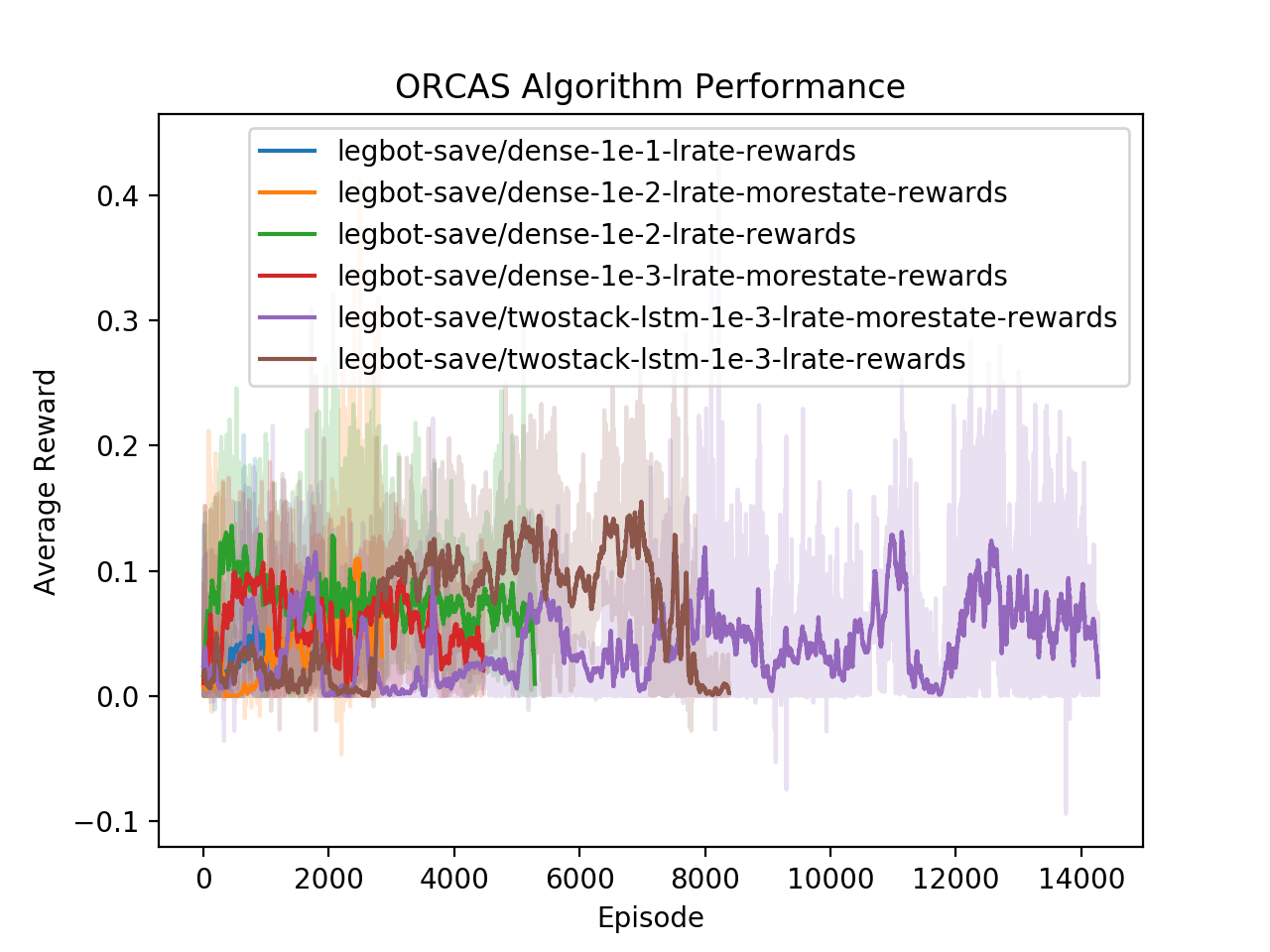
Finally, we also have results from some architectures that did not work as well. Here I experimented with different learning rates, state information and neural network architectures. All of these networks have two hidden layers with 32 units in each layer. The runs labelled "morestate" are after adding more state information to the input state vector for the network. Notice that these networks had trouble reaching over even 0.1 average reward while the two networks above very quickly passed the same mark.
Overall, one thing is clear. There is still a lot more training to be done before these robots will be able to walk. While the two best performing settings seem promising, there may be other architectures that learn this task much better. Further experimentation is required.