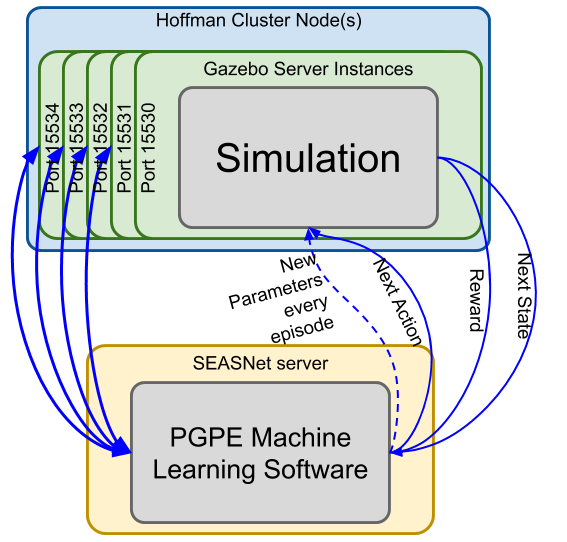
The ORCAS team has designed a parallel framework to improve training speeds for parameter optimization. So far, the parameter exploration algorithm used a single instance of Gazebo to run simulations. However, this proved to be a bottleneck since the simulation was computationally intensive and took longer for more complex parameterized robots. Furthermore, since both the machine learning algorithm and the simulations were run on personal machines, issues like battery life and internet availability caused problems as well.
To resolve these issues, we desgined a system using which the simulations will run parallely. This allows for the pgpe algorithm to be blocked for less time, therefore making training more efficient. To this end, we make use of nodes from hoffman cluster. This gives us access to multiple processors, each of which is responsible for running simulations on a seperate instance of gazebo. Each instance will be assigned a different port number so that communication between the gazebo servers and the machine learning algorithm will be possible.
The parameter exploration algorithm will then be run on the SEASNet servers. This choice was made since the SEASNet servers are unlikely to suffer network issues or be turned off. Furthermore, they are in the same network as the Hoffman cluster, so communication between the two systems will not be an issue. This program will recieve reward and next state information from all the seperate instances of gazebo, and provide action and parameter information to them all as well.